Reclassifying data
Contents
Reclassifying data#
Reclassifying data based on specific criteria is a common task when doing GIS analysis. The purpose of this lesson is to see how we can reclassify values based on some criteria. We could, for example, classify information based on travel times and housing prices using these criteria:
if travel time to my work is less than 30 minutes, AND
the rent of the apartment is less than 1000 € per month
If both criteria are met: I go to see the appartment and try to rent it If not: I continue to look for something else
In this tutorial, we will:
Use classification schemes from the PySAL mapclassify library to classify travel times into multiple classes.
Create a custom classifier to classify travel times and distances in order to find out good locations to buy an apartment with these conditions:
good public transport accessibility to city center
bit further away from city center where the prices are presumably lower
Input data#
We will use Travel Time Matrix data from Helsinki that contains travel time and distance information for routes between all 250 m x 250 m grid cell centroids (n = 13231) in the Capital Region of Helsinki by walking, cycling, public transportation and car.
import pathlib
NOTEBOOK_PATH = pathlib.Path().resolve()
DATA_DIRECTORY = NOTEBOOK_PATH / "data"
import geopandas
accessibility_grid = geopandas.read_file(
DATA_DIRECTORY
/ "helsinki_region_travel_times_to_railway_station"
/ "helsinki_region_travel_times_to_railway_station.gpkg"
)
accessibility_grid.head()
| car_m_d | car_m_t | car_r_d | car_r_t | from_id | pt_m_d | pt_m_t | pt_m_tt | pt_r_d | pt_r_t | pt_r_tt | to_id | walk_d | walk_t | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 32297 | 43 | 32260 | 48 | 5785640 | 32616 | 116 | 147 | 32616 | 108 | 139 | 5975375 | 32164 | 459 | POLYGON ((382000.000 6697750.000, 381750.000 6... |
| 1 | 32508 | 43 | 32471 | 49 | 5785641 | 32822 | 119 | 145 | 32822 | 111 | 133 | 5975375 | 29547 | 422 | POLYGON ((382250.000 6697750.000, 382000.000 6... |
| 2 | 30133 | 50 | 31872 | 56 | 5785642 | 32940 | 121 | 146 | 32940 | 113 | 133 | 5975375 | 29626 | 423 | POLYGON ((382500.000 6697750.000, 382250.000 6... |
| 3 | 32690 | 54 | 34429 | 60 | 5785643 | 33233 | 125 | 150 | 33233 | 117 | 144 | 5975375 | 29919 | 427 | POLYGON ((382750.000 6697750.000, 382500.000 6... |
| 4 | 31872 | 42 | 31834 | 48 | 5787544 | 32127 | 109 | 126 | 32127 | 101 | 121 | 5975375 | 31674 | 452 | POLYGON ((381250.000 6697500.000, 381000.000 6... |
Common classifiers#
Classification schemes for thematic maps#
PySAL -module is an extensive Python library for spatial analysis. It also includes all of the most common data classifiers that are used commonly e.g. when visualizing data. Available map classifiers in pysal’s mapclassify -module:
Box Plot
Equal Interval
Fisher Jenks
Fisher Jenks Sampled
HeadTail Breaks
Jenks Caspall
Jenks Caspall Forced
Jenks Caspall Sampled
Max P Classifier
Maximum Breaks
Natural Breaks
Quantiles
Percentiles
Std Mean
User Defined
There are plenty of different variables in the accessibility data set (see
from here the
description
for all attributes) but what we are interested in are columns called pt_r_tt
which is telling the time in minutes that it takes to reach city center from
different parts of the city, and walk_d that tells the network distance by
roads to reach city center from different parts of the city (almost equal to
Euclidian distance).
The NoData values are presented with value -1. Thus we need to remove the No Data values first.
# Include only data that is above or equal to 0
accessibility_grid = accessibility_grid.loc[accessibility_grid["pt_r_tt"] >=0]
Let’s plot the data and see how it looks like
cmapparameter defines the color map. Read more about choosing colormaps in matplotlibschemeoption scales the colors according to a classification scheme (requiresmapclassifymodule to be installed):
# Plot using 9 classes and classify the values using "Natural Breaks" classification
accessibility_grid.plot(column="pt_r_tt", scheme="Natural_Breaks", k=9, cmap="RdYlBu", linewidth=0, legend=True)
<AxesSubplot: >
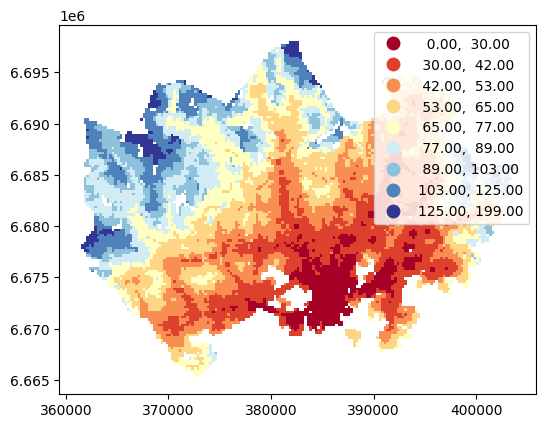
As we can see from this map, the travel times are lower in the south where the city center is located but there are some areas of “good” accessibility also in some other areas (where the color is red).
Let’s also make a plot about walking distances:
# Plot walking distance
accessibility_grid.plot(column="walk_d", scheme="Natural_Breaks", k=9, cmap="RdYlBu", linewidth=0, legend=True)
<AxesSubplot: >
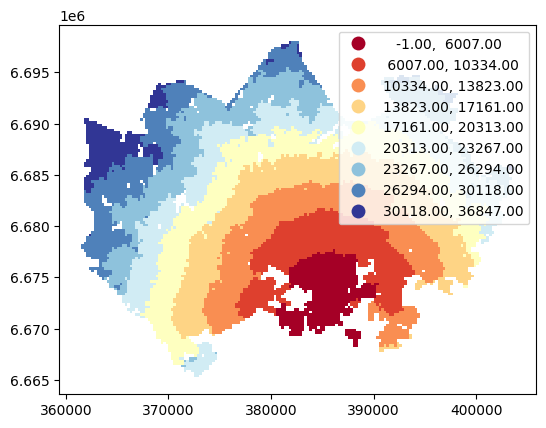
Okay, from here we can see that the walking distances (along road network) reminds more or less Euclidian distances.
Applying classifiers to data#
As mentioned, the scheme option defines the classification scheme using
pysal/mapclassify. Let’s have a closer look at how these classifiers work.
import mapclassify
Natural Breaks#
mapclassify.NaturalBreaks(y=accessibility_grid["pt_r_tt"], k=9)
NaturalBreaks
Interval Count
------------------------
[ 0.00, 32.00] | 1037
( 32.00, 44.00] | 2386
( 44.00, 54.00] | 2228
( 54.00, 65.00] | 2088
( 65.00, 78.00] | 1761
( 78.00, 92.00] | 1694
( 92.00, 108.00] | 1087
(108.00, 129.00] | 557
(129.00, 199.00] | 182
Quantiles (default is 5 classes):#
mapclassify.Quantiles(y=accessibility_grid["pt_r_tt"])
Quantiles
Interval Count
------------------------
[ 0.00, 41.00] | 2674
( 41.00, 52.00] | 2576
( 52.00, 66.00] | 2623
( 66.00, 85.00] | 2616
( 85.00, 199.00] | 2531
Extract threshold values#
It’s possible to extract the threshold values into an array:
classifier = mapclassify.NaturalBreaks(y=accessibility_grid["pt_r_tt"], k=9)
classifier.bins
array([ 28., 40., 52., 63., 74., 87., 102., 125., 199.])
Let’s apply one of the Pysal classifiers into our data and classify the
travel times by public transport into 9 classes
The classifier needs to be initialized first with make() function that takes
the number of desired classes as input parameter
# Create a Natural Breaks classifier
classifier = mapclassify.NaturalBreaks.make(k=9)
Now we can apply that classifier into our data by using
apply-function
# Classify the data
classifications = accessibility_grid[["pt_r_tt"]].apply(classifier)
# Let's see what we have
classifications.head()
| pt_r_tt | |
|---|---|
| 0 | 8 |
| 1 | 8 |
| 2 | 8 |
| 3 | 8 |
| 4 | 7 |
type(classifications)
pandas.core.frame.DataFrame
Okay, so now we have a DataFrame where our input column was classified into 9 different classes (numbers 1-9) based on Natural Breaks classification.
We can also add the classification values directly into a new column in our dataframe:
# Rename the column so that we know that it was classified with natural breaks
accessibility_grid["nb_pt_r_tt"] = accessibility_grid[["pt_r_tt"]].apply(classifier)
# Check the original values and classification
accessibility_grid[["pt_r_tt", "nb_pt_r_tt"]].head()
| pt_r_tt | nb_pt_r_tt | |
|---|---|---|
| 0 | 139 | 8 |
| 1 | 133 | 8 |
| 2 | 133 | 8 |
| 3 | 144 | 8 |
| 4 | 121 | 7 |
Great, now we have those values in our accessibility GeoDataFrame. Let’s visualize the results and see how they look.
# Plot
accessibility_grid.plot(column="nb_pt_r_tt", linewidth=0, legend=True)
<AxesSubplot: >
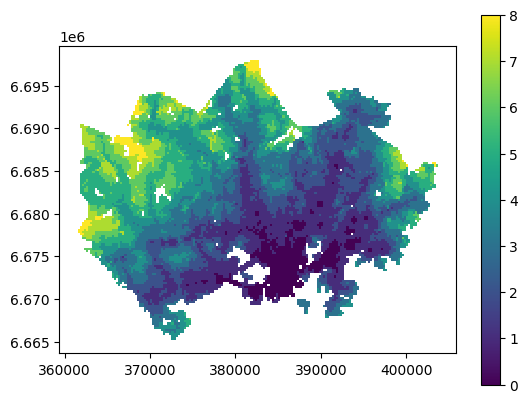
And here we go, now we have a map where we have used one of the common classifiers to classify our data into 9 classes.
Plotting a histogram#
A histogram is a graphic representation of the distribution of the data. When classifying the data, it’s always good to consider how the data is distributed, and how the classification shceme divides values into different ranges.
plot the histogram using pandas.DataFrame.plot.hist
Number of histogram bins (groups of data) can be controlled using the parameter
bins:
# Histogram for public transport rush hour travel time
accessibility_grid["pt_r_tt"].plot.hist(bins=50)
<AxesSubplot: ylabel='Frequency'>
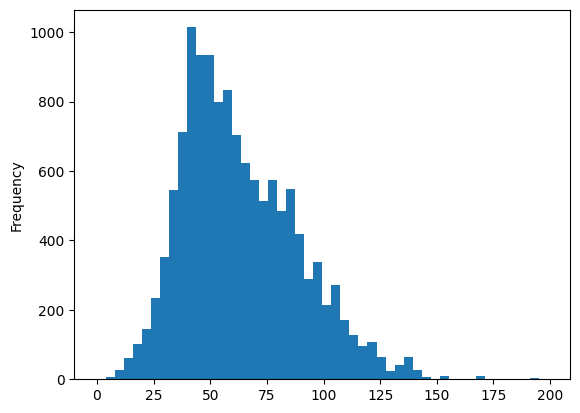
Let’s also add threshold values on thop of the histogram as vertical lines.
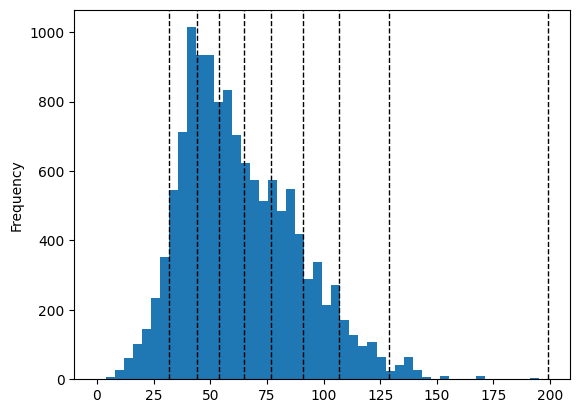
Natural Breaks:
import matplotlib.pyplot as plt
# Define classifier
classifier = mapclassify.NaturalBreaks(y=accessibility_grid["pt_r_tt"], k=9)
# Plot histogram for public transport rush hour travel time
accessibility_grid["pt_r_tt"].plot.hist(bins=50)
# Add vertical lines for class breaks
for break_point in classifier.bins:
plt.axvline(break_point, color="k", linestyle="dashed", linewidth=1)
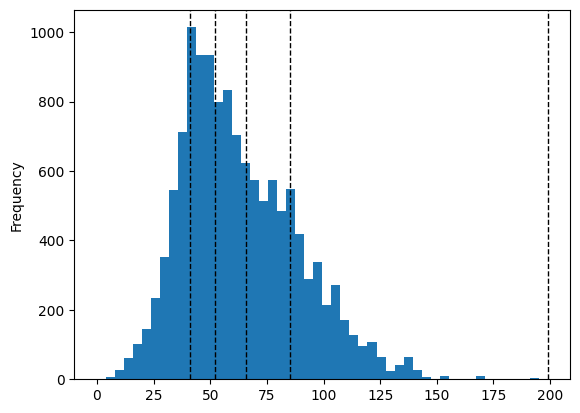
Quantiles:
# Define classifier
classifier = mapclassify.Quantiles(y=accessibility_grid['pt_r_tt'])
# Plot histogram for public transport rush hour travel time
accessibility_grid["pt_r_tt"].plot.hist(bins=50)
for break_point in classifier.bins:
plt.axvline(break_point, color="k", linestyle="dashed", linewidth=1)
Check your understanding
Select another column from the data (for example, travel times by car:
car_r_t). Do the following visualizations using one of the classification
schemes available from
pysal/mapclassify:
histogram with vertical lines showing the classification bins
thematic map using the classification scheme
Applying a custom classifier#
Multicriteria data classification#
Let’s classify the geometries into two classes based
on a given threshold -parameter. If the area of a polygon is lower than the
threshold value (e.g., a certain distance), the output column will get a value
0, if it is larger, it will get a value 1. This kind of classification is often
called a binary
classification.
To classify each row of our GeoDataFrame we can iterate over each row or we can apply a function for each row. In our case, we will apply a lambda function for each row in our GeoDataFrame, which returns a value based on the conditions we provide.
Let’s do our classification based on two criteria: and find out grid cells
Grid cells where the travel time is lower or equal to 20 minutes
and they are further away than 4 km (4000 meters) from the city center.
Let’s first see how to classify a single row:
accessibility_grid.iloc[0]["pt_r_tt"] < 20 and accessibility_grid.iloc[0]["walk_d"] > 4000
False
int(accessibility_grid.iloc[11293]["pt_r_tt"] < 20 and accessibility_grid.iloc[11293]["walk_d"] > 4000)
1
Let’s now apply this to our GeoDataFrame and save it to a column called "suitable_area":
accessibility_grid["suitable_area"] = accessibility_grid.apply(lambda row: int(row["pt_r_tt"] < 20 and row["walk_d"] > 4000), axis=1)
accessibility_grid.head()
| car_m_d | car_m_t | car_r_d | car_r_t | from_id | pt_m_d | pt_m_t | pt_m_tt | pt_r_d | pt_r_t | pt_r_tt | to_id | walk_d | walk_t | geometry | nb_pt_r_tt | suitable_area | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 32297 | 43 | 32260 | 48 | 5785640 | 32616 | 116 | 147 | 32616 | 108 | 139 | 5975375 | 32164 | 459 | POLYGON ((382000.000 6697750.000, 381750.000 6... | 8 | 0 |
| 1 | 32508 | 43 | 32471 | 49 | 5785641 | 32822 | 119 | 145 | 32822 | 111 | 133 | 5975375 | 29547 | 422 | POLYGON ((382250.000 6697750.000, 382000.000 6... | 8 | 0 |
| 2 | 30133 | 50 | 31872 | 56 | 5785642 | 32940 | 121 | 146 | 32940 | 113 | 133 | 5975375 | 29626 | 423 | POLYGON ((382500.000 6697750.000, 382250.000 6... | 8 | 0 |
| 3 | 32690 | 54 | 34429 | 60 | 5785643 | 33233 | 125 | 150 | 33233 | 117 | 144 | 5975375 | 29919 | 427 | POLYGON ((382750.000 6697750.000, 382500.000 6... | 8 | 0 |
| 4 | 31872 | 42 | 31834 | 48 | 5787544 | 32127 | 109 | 126 | 32127 | 101 | 121 | 5975375 | 31674 | 452 | POLYGON ((381250.000 6697500.000, 381000.000 6... | 7 | 0 |
Okey we have new values in suitable_area -column.
How many Polygons are suitable for us? Let’s find out by using a Pandas function called
value_counts()that return the count of different values in our column.
# Get value counts
accessibility_grid["suitable_area"].value_counts()
0 13011
1 9
Name: suitable_area, dtype: int64
Okay, so there seems to be nine suitable locations for us where we can try to find an appartment to buy.
Let’s see where they are located:
# Plot
accessibility_grid.plot(column="suitable_area", linewidth=0)
<AxesSubplot: >
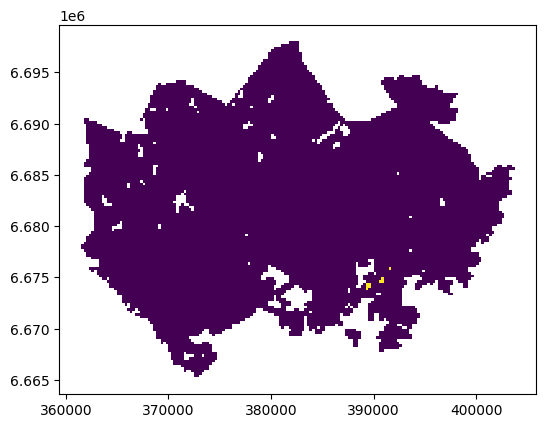
A-haa, okay so we can see that suitable places for us with our criteria seem to be located in the eastern part from the city center. Actually, those locations are along the metro line which makes them good locations in terms of travel time to city center since metro is really fast travel mode.