Spatial join¶
Spatial join is yet another classic GIS problem. Getting attributes from one layer and transferring them into another layer based on their spatial relationship is something you most likely need to do on a regular basis.
In the previous section we learned how to perform a Point in Polygon query.
We can now use the same logic to conduct a spatial join between two layers based on their
spatial relationship. We could, for example, join the attributes of a polygon layer into a point layer where each point would get the
attributes of a polygon that contains the point.
Luckily, spatial join is already implemented in Geopandas, thus we do not need to create our own function for doing it. There are three possible types of
join that can be applied in spatial join that are determined with op -parameter in the gpd.sjoin() -function:
"intersects""within""contains"
Sounds familiar? Yep, all of those spatial relationships were discussed in the Point in Polygon lesson, thus you should know how they work.
Furthermore, pay attention to the different options for the type of join via the how parameter; “left”, “right” and “inner”. You can read more about these options in the geopandas sjoin documentation and pandas guide for merge, join and concatenate
Let’s perform a spatial join between these two layers:
Addresses: the geocoded address-point (we created this Shapefile in the geocoding tutorial)
Population grid: 250m x 250m grid polygon layer that contains population information from the Helsinki Region.
The population grid a dataset is produced by the Helsinki Region Environmental Services Authority (HSY) (see this page to access data from different years).
You can download the data from from this link in the Helsinki Region Infroshare (HRI) open data portal.
Here, we will access the data directly from the HSY wfs:
import geopandas as gpd
from pyproj import CRS
import requests
import geojson
# Specify the url for web feature service
url = 'https://kartta.hsy.fi/geoserver/wfs'
# Specify parameters (read data in json format).
# Available feature types in this particular data source: http://geo.stat.fi/geoserver/vaestoruutu/wfs?service=wfs&version=2.0.0&request=describeFeatureType
params = dict(service='WFS',
version='2.0.0',
request='GetFeature',
typeName='asuminen_ja_maankaytto:Vaestotietoruudukko_2018',
outputFormat='json')
# Fetch data from WFS using requests
r = requests.get(url, params=params)
# Create GeoDataFrame from geojson
pop = gpd.GeoDataFrame.from_features(geojson.loads(r.content))
Check the result:
pop.head()
| geometry | index | asukkaita | asvaljyys | ika0_9 | ika10_19 | ika20_29 | ika30_39 | ika40_49 | ika50_59 | ika60_69 | ika70_79 | ika_yli80 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | MULTIPOLYGON Z (((25476499.999 6674248.999 0.0... | 3342 | 108 | 45 | 11 | 23 | 6 | 7 | 26 | 17 | 8 | 6 | 4 |
| 1 | MULTIPOLYGON Z (((25476749.997 6674498.998 0.0... | 3503 | 273 | 35 | 35 | 24 | 52 | 62 | 40 | 26 | 25 | 9 | 0 |
| 2 | MULTIPOLYGON Z (((25476999.994 6675749.004 0.0... | 3660 | 239 | 34 | 46 | 24 | 24 | 45 | 33 | 30 | 25 | 10 | 2 |
| 3 | MULTIPOLYGON Z (((25476999.994 6675499.004 0.0... | 3661 | 202 | 30 | 52 | 37 | 13 | 36 | 43 | 11 | 4 | 3 | 3 |
| 4 | MULTIPOLYGON Z (((25476999.994 6675249.005 0.0... | 3662 | 261 | 30 | 64 | 32 | 36 | 64 | 34 | 20 | 6 | 3 | 2 |
Okey so we have multiple columns in the dataset but the most important
one here is the column asukkaita (“population” in Finnish) that
tells the amount of inhabitants living under that polygon.
Let’s change the name of that column into
pop18so that it is more intuitive. As you might remember, we can easily rename (Geo)DataFrame column names using therename()function where we pass a dictionary of new column names like this:columns={'oldname': 'newname'}.
# Change the name of a column
pop = pop.rename(columns={'asukkaita': 'pop18'})
# Check the column names
pop.columns
Index(['geometry', 'index', 'pop18', 'asvaljyys', 'ika0_9', 'ika10_19',
'ika20_29', 'ika30_39', 'ika40_49', 'ika50_59', 'ika60_69', 'ika70_79',
'ika_yli80'],
dtype='object')
Let’s also get rid of all unnecessary columns by selecting only columns that we need i.e. pop18 and geometry
# Subset columns
pop = pop[["pop18", "geometry"]]
pop.head()
| pop18 | geometry | |
|---|---|---|
| 0 | 108 | MULTIPOLYGON Z (((25476499.999 6674248.999 0.0... |
| 1 | 273 | MULTIPOLYGON Z (((25476749.997 6674498.998 0.0... |
| 2 | 239 | MULTIPOLYGON Z (((25476999.994 6675749.004 0.0... |
| 3 | 202 | MULTIPOLYGON Z (((25476999.994 6675499.004 0.0... |
| 4 | 261 | MULTIPOLYGON Z (((25476999.994 6675249.005 0.0... |
Now we have cleaned the data and have only those columns that we need for our analysis.
Join the layers¶
Now we are ready to perform the spatial join between the two layers that
we have. The aim here is to get information about how many people live
in a polygon that contains an individual address-point . Thus, we want
to join attributes from the population layer we just modified into the
addresses point layer addresses.shp that we created trough gecoding in the previous section.
Read the addresses layer into memory:
# Addresses filpath
addr_fp = r"data/addresses.shp"
# Read data
addresses = gpd.read_file(addr_fp)
# Check the head of the file
addresses.head()
| address | id | addr | geometry | |
|---|---|---|---|---|
| 0 | Ruoholahti, 14, Itämerenkatu, Ruoholahti, Läns... | 1000 | Itämerenkatu 14, 00101 Helsinki, Finland | POINT (24.91556 60.16320) |
| 1 | Kamppi, 1, Kampinkuja, Kamppi, Eteläinen suurp... | 1001 | Kampinkuja 1, 00100 Helsinki, Finland | POINT (24.93169 60.16902) |
| 2 | Kauppakeskus Citycenter, 8, Kaivokatu, Keskust... | 1002 | Kaivokatu 8, 00101 Helsinki, Finland | POINT (24.94179 60.16989) |
| 3 | Hermannin rantatie, Verkkosaari, Kalasatama, S... | 1003 | Hermannin rantatie 1, 00580 Helsinki, Finland | POINT (24.97783 60.18892) |
| 4 | Hesburger, 9, Tyynenmerenkatu, Jätkäsaari, Län... | 1005 | Tyynenmerenkatu 9, 00220 Helsinki, Finland | POINT (24.92160 60.15665) |
In order to do a spatial join, the layers need to be in the same projection
Check the crs of input layers:
addresses.crs
<Geographic 2D CRS: EPSG:4326>
Name: WGS 84
Axis Info [ellipsoidal]:
- Lat[north]: Geodetic latitude (degree)
- Lon[east]: Geodetic longitude (degree)
Area of Use:
- name: World
- bounds: (-180.0, -90.0, 180.0, 90.0)
Datum: World Geodetic System 1984
- Ellipsoid: WGS 84
- Prime Meridian: Greenwich
pop.crs
If the crs information is missing from the population grid, we can define the coordinate reference system as ETRS GK-25 (EPSG:3879) because we know what it is based on the population grid metadata.
# Define crs
pop.crs = CRS.from_epsg(3879).to_wkt()
pop.crs
<Projected CRS: EPSG:3879>
Name: ETRS89 / GK25FIN
Axis Info [cartesian]:
- N[north]: Northing (metre)
- E[east]: Easting (metre)
Area of Use:
- name: Finland - 24.5°E to 25.5°E onshore nominal
- bounds: (24.5, 59.94, 25.5, 68.9)
Coordinate Operation:
- name: Finland Gauss-Kruger zone 25
- method: Transverse Mercator
Datum: European Terrestrial Reference System 1989
- Ellipsoid: GRS 1980
- Prime Meridian: Greenwich
# Are the layers in the same projection?
addresses.crs == pop.crs
False
Let’s re-project addresses to the projection of the population layer:
addresses = addresses.to_crs(pop.crs)
Let’s make sure that the coordinate reference system of the layers are identical
# Check the crs of address points
print(addresses.crs)
# Check the crs of population layer
print(pop.crs)
# Do they match now?
addresses.crs == pop.crs
PROJCRS["ETRS89 / GK25FIN",BASEGEOGCRS["ETRS89",DATUM["European Terrestrial Reference System 1989",ELLIPSOID["GRS 1980",6378137,298.257222101,LENGTHUNIT["metre",1]]],PRIMEM["Greenwich",0,ANGLEUNIT["degree",0.0174532925199433]],ID["EPSG",4258]],CONVERSION["Finland Gauss-Kruger zone 25",METHOD["Transverse Mercator",ID["EPSG",9807]],PARAMETER["Latitude of natural origin",0,ANGLEUNIT["degree",0.0174532925199433],ID["EPSG",8801]],PARAMETER["Longitude of natural origin",25,ANGLEUNIT["degree",0.0174532925199433],ID["EPSG",8802]],PARAMETER["Scale factor at natural origin",1,SCALEUNIT["unity",1],ID["EPSG",8805]],PARAMETER["False easting",25500000,LENGTHUNIT["metre",1],ID["EPSG",8806]],PARAMETER["False northing",0,LENGTHUNIT["metre",1],ID["EPSG",8807]]],CS[Cartesian,2],AXIS["northing (N)",north,ORDER[1],LENGTHUNIT["metre",1]],AXIS["easting (E)",east,ORDER[2],LENGTHUNIT["metre",1]],USAGE[SCOPE["unknown"],AREA["Finland - 24.5°E to 25.5°E onshore nominal"],BBOX[59.94,24.5,68.9,25.5]],ID["EPSG",3879]]
PROJCRS["ETRS89 / GK25FIN",BASEGEOGCRS["ETRS89",DATUM["European Terrestrial Reference System 1989",ELLIPSOID["GRS 1980",6378137,298.257222101,LENGTHUNIT["metre",1]]],PRIMEM["Greenwich",0,ANGLEUNIT["degree",0.0174532925199433]],ID["EPSG",4258]],CONVERSION["Finland Gauss-Kruger zone 25",METHOD["Transverse Mercator",ID["EPSG",9807]],PARAMETER["Latitude of natural origin",0,ANGLEUNIT["degree",0.0174532925199433],ID["EPSG",8801]],PARAMETER["Longitude of natural origin",25,ANGLEUNIT["degree",0.0174532925199433],ID["EPSG",8802]],PARAMETER["Scale factor at natural origin",1,SCALEUNIT["unity",1],ID["EPSG",8805]],PARAMETER["False easting",25500000,LENGTHUNIT["metre",1],ID["EPSG",8806]],PARAMETER["False northing",0,LENGTHUNIT["metre",1],ID["EPSG",8807]]],CS[Cartesian,2],AXIS["northing (N)",north,ORDER[1],LENGTHUNIT["metre",1]],AXIS["easting (E)",east,ORDER[2],LENGTHUNIT["metre",1]],USAGE[SCOPE["unknown"],AREA["Finland - 24.5°E to 25.5°E onshore nominal"],BBOX[59.94,24.5,68.9,25.5]],ID["EPSG",3879]]
True
Now they should be identical. Thus, we can be sure that when doing spatial queries between layers the locations match and we get the right results e.g. from the spatial join that we are conducting here.
Let’s now join the attributes from
popGeoDataFrame intoaddressesGeoDataFrame by usinggpd.sjoin()-function:
# Make a spatial join
join = gpd.sjoin(addresses, pop, how="inner", op="within")
join.head()
| address | id | addr | geometry | index_right | pop18 | |
|---|---|---|---|---|---|---|
| 0 | Ruoholahti, 14, Itämerenkatu, Ruoholahti, Läns... | 1000 | Itämerenkatu 14, 00101 Helsinki, Finland | POINT (25495311.608 6672258.695) | 1514 | 515 |
| 1 | Kamppi, 1, Kampinkuja, Kamppi, Eteläinen suurp... | 1001 | Kampinkuja 1, 00100 Helsinki, Finland | POINT (25496207.840 6672906.173) | 1600 | 182 |
| 4 | Hesburger, 9, Tyynenmerenkatu, Jätkäsaari, Län... | 1005 | Tyynenmerenkatu 9, 00220 Helsinki, Finland | POINT (25495645.995 6671528.068) | 1550 | 1435 |
| 6 | Itäväylä, Vartioharju, Vartiokylä, Helsinki, H... | 1007 | Itäväylä 3, 00950 Helsinki, Finland | POINT (25506221.445 6678859.295) | 3007 | 155 |
| 7 | Tapulikaupungintie, Tapulikaupunki, Suutarila,... | 1008 | Tapulikaupungintie 3, 00750 Helsinki, Finland | POINT (25501664.428 6685108.440) | 2264 | 262 |
Awesome! Now we have performed a successful spatial join where we got
two new columns into our join GeoDataFrame, i.e. index_right
that tells the index of the matching polygon in the population grid and
pop18 which is the population in the cell where the address-point is
located.
Let’s still check how many rows of data we have now:
len(join)
27
Did we lose some data here?
Check how many addresses we had originally:
len(addresses)
34
If we plot the layers on top of each other, we can observe that some of the points are located outside the populated grid squares (increase figure size if you can’t see this properly!)
import matplotlib.pyplot as plt
# Create a figure with one subplot
fig, ax = plt.subplots(figsize=(15,8))
# Plot population grid
pop.plot(ax=ax)
# Plot points
addresses.plot(ax=ax, color='red', markersize=5)
<AxesSubplot:>
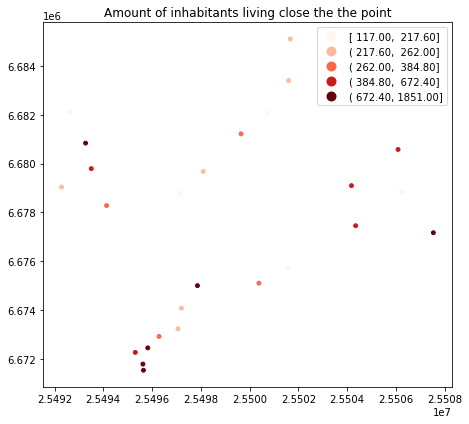
Let’s also visualize the joined output:
Plot the points and use the pop18 column to indicate the color.
cmap -parameter tells to use a sequential colormap for the
values, markersize adjusts the size of a point, scheme parameter can be used to adjust the classification method based on pysal, and legend tells that we want to have a legend:
# Create a figure with one subplot
fig, ax = plt.subplots(figsize=(10,6))
# Plot the points with population info
join.plot(ax=ax, column='pop18', cmap="Reds", markersize=15, scheme='quantiles', legend=True);
# Add title
plt.title("Amount of inhabitants living close the the point");
# Remove white space around the figure
plt.tight_layout()
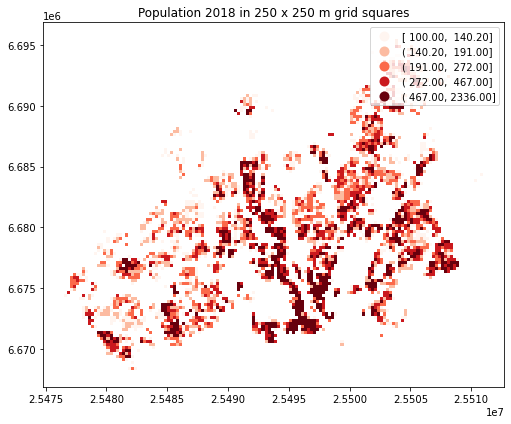
In a similar way, we can plot the original population grid and check the overall population distribution in Helsinki:
# Create a figure with one subplot
fig, ax = plt.subplots(figsize=(10,6))
# Plot the grid with population info
pop.plot(ax=ax, column='pop18', cmap="Reds", scheme='quantiles', legend=True);
# Add title
plt.title("Population 2018 in 250 x 250 m grid squares");
# Remove white space around the figure
plt.tight_layout()
Finally, let’s save the result point layer into a file:
# Output path
outfp = r"data/addresses_population.shp"
# Save to disk
join.to_file(outfp)