Network analysis in Python¶
Finding a shortest path using a specific street network is a common GIS problem that has many practical applications. For example navigators are one of those “every-day” applications where routing using specific algorithms is used to find the optimal route between two (or multiple) points.
It is also possible to perform network analysis such as tranposrtation routing in Python. Networkx is a Python module that provides tools for analyzing networks in various different ways. It also contains algorithms such as Dijkstra’s algorithm or A* algoritm that are commonly used to find shortest paths along transportation network.
To be able to conduct network analysis, it is, of course, necessary to have a network that is used for the analyses. OSMnx package that we just explored in previous tutorial, makes it really easy to retrieve routable networks from OpenStreetMap with different transport modes (walking, cycling and driving). OSMnx also combines some functionalities from networkx module to make it straightforward to conduct routing along OpenStreetMap data.
Next we will test the routing functionalities of OSMnx by finding a shortest path between two points based on drivable roads. With tiny modifications, it is also possible to repeat the analysis for the walkable street network.
Get the network¶
Let’s again start by importing the required modules
import osmnx as ox
import networkx as nx
import geopandas as gpd
import matplotlib.pyplot as plt
import pandas as pd
from pyproj import CRS
When fetching netowrk data from OpenStreetMap using OSMnx, it is possible to define the type of street network using the network_type parameter (options: drive, walk and bike).
Let’s download the OSM data from Kamppi but this only the drivable network. Alternatively, you can also fetch the walkable network (this will take a bit longer time).
place_name = "Kamppi, Helsinki, Finland"
graph = ox.graph_from_place(place_name, network_type='drive')
Plot the graph:
fig, ax = ox.plot_graph(graph)
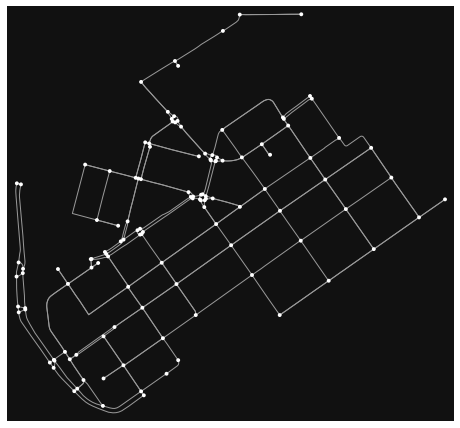
Okey so now we have retrieved only such streets where it is possible to drive with a car. Let’s confirm this by taking a look at the attributes of the street network. Easiest way to do this is to convert the graph (nodes and edges) into GeoDataFrames.
Converting graph into a GeoDataFrame can be done with function graph_to_gdfs() that we already used in previous tutorial. With parameters nodes and edges, it is possible to control whether to retrieve both nodes and edges from the graph.
# Retrieve only edges from the graph
edges = ox.graph_to_gdfs(graph, nodes=False, edges=True)
# Check columns
edges.columns
Index(['osmid', 'oneway', 'lanes', 'name', 'highway', 'maxspeed', 'length',
'geometry', 'junction', 'bridge', 'access', 'u', 'v', 'key'],
dtype='object')
# Check crs
edges.crs
<Geographic 2D CRS: EPSG:4326>
Name: WGS 84
Axis Info [ellipsoidal]:
- Lat[north]: Geodetic latitude (degree)
- Lon[east]: Geodetic longitude (degree)
Area of Use:
- name: World
- bounds: (-180.0, -90.0, 180.0, 90.0)
Datum: World Geodetic System 1984
- Ellipsoid: WGS 84
- Prime Meridian: Greenwich
Note that the CRS of the GeoDataFrame is be WGS84 (epsg: 4326).
edges.head()
| osmid | oneway | lanes | name | highway | maxspeed | length | geometry | junction | bridge | access | u | v | key | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 23856784 | True | 2 | Mechelininkatu | primary | 40 | 40.885 | LINESTRING (24.92106 60.16479, 24.92095 60.164... | NaN | NaN | NaN | 25216594 | 1372425714 | 0 |
| 1 | [29977177, 30470347] | True | 3 | Mechelininkatu | primary | 40 | 16.601 | LINESTRING (24.92103 60.16366, 24.92104 60.163... | NaN | NaN | NaN | 25238874 | 1372425713 | 0 |
| 2 | [372440330, 8135861] | True | 2 | NaN | primary | 40 | 25.190 | LINESTRING (24.92129 60.16463, 24.92127 60.164... | NaN | NaN | NaN | 25238944 | 25216594 | 0 |
| 3 | [25514547, 677423564, 30288797, 30288799] | True | [2, 3] | Mechelininkatu | primary | 40 | 242.476 | LINESTRING (24.92129 60.16463, 24.92136 60.164... | NaN | NaN | NaN | 25238944 | 319896278 | 0 |
| 4 | [30568275, 36729015, 316590744, 316590745, 316... | True | NaN | Fredrikinkatu | tertiary | 30 | 139.090 | LINESTRING (24.93702 60.16433, 24.93700 60.164... | NaN | NaN | NaN | 25291537 | 25291591 | 0 |
Okey, so we have quite many columns in our GeoDataFrame. Most of the columns are fairly self-explanatory but the following table describes all of them.
Most of the attributes come directly from the OpenStreetMap, however, columns u and v are Networkx specific ids. You can click on the links to get more information about each attribute:
Column |
Description |
Data type |
|---|---|---|
Bridge feature |
boolean |
|
geometry |
Geometry of the feature |
Shapely.geometry |
Tag for roads (road type) |
str / list |
|
Number of lanes |
int (or nan) |
|
Length of feature (meters) |
float |
|
maximum legal speed limit |
int /list |
|
Name of the (street) element |
str (or nan) |
|
One way road |
boolean |
|
Unique ids for the element |
list |
|
The first node of edge |
int |
|
The last node of edge |
int |
Let’s take a look what kind of features we have in the highway column:
edges['highway'].value_counts()
residential 113
tertiary 78
primary 26
secondary 17
unclassified 10
living_street 4
primary_link 1
Name: highway, dtype: int64
Okey, now we can confirm that as a result our street network indeed only contains such streets where it is allowed to drive with a car as there are no e.g. cycleways or footways included in the data.
As the data is in WGS84 format, we might want to reproject our data into a metric system before proceeding to the shortest path analysis. We can re-project the graph from latitudes and longitudes to an appropriate UTM zone using the project_graph() function from OSMnx.
# Project the data
graph_proj = ox.project_graph(graph)
# Get Edges and Nodes
nodes_proj, edges_proj = ox.graph_to_gdfs(graph_proj, nodes=True, edges=True)
print("Coordinate system:", edges_proj.crs)
Coordinate system: +proj=utm +zone=35 +ellps=WGS84 +datum=WGS84 +units=m +no_defs +type=crs
edges_proj.head()
| osmid | oneway | lanes | name | highway | maxspeed | length | geometry | junction | bridge | access | u | v | key | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 23856784 | True | 2 | Mechelininkatu | primary | 40 | 40.885 | LINESTRING (384631.322 6671580.071, 384624.750... | NaN | NaN | NaN | 25216594 | 1372425714 | 0 |
| 1 | [29977177, 30470347] | True | 3 | Mechelininkatu | primary | 40 | 16.601 | LINESTRING (384625.787 6671454.380, 384626.281... | NaN | NaN | NaN | 25238874 | 1372425713 | 0 |
| 2 | [372440330, 8135861] | True | 2 | NaN | primary | 40 | 25.190 | LINESTRING (384643.473 6671561.534, 384643.045... | NaN | NaN | NaN | 25238944 | 25216594 | 0 |
| 3 | [25514547, 677423564, 30288797, 30288799] | True | [2, 3] | Mechelininkatu | primary | 40 | 242.476 | LINESTRING (384643.473 6671561.534, 384648.006... | NaN | NaN | NaN | 25238944 | 319896278 | 0 |
| 4 | [30568275, 36729015, 316590744, 316590745, 316... | True | NaN | Fredrikinkatu | tertiary | 30 | 139.090 | LINESTRING (385515.553 6671500.134, 385514.557... | NaN | NaN | NaN | 25291537 | 25291591 | 0 |
Okey, as we can see from the CRS the data is now in UTM projection using zone 35 which is the one used for Finland, and indeed the orientation of the map and the geometry values also confirm this.
Furthermore, we can check the epsg code of this projection using pyproj CRS:
CRS(edges_proj.crs).to_epsg()
32635
Indeed, the projection is now WGS 84 / UTM zone 35N, EPSG:32635.
Analyzing the network properties¶
Now as we have seen some of the basic functionalities of OSMnx such as downloading the data and converting data from graph to GeoDataFrame, we can take a look some of the analytical features of omsnx. Osmnx includes many useful functionalities to extract information about the network.
To calculate some of the basic street network measures we can use basic_stats() function in OSMnx:
# Calculate network statistics
stats = ox.basic_stats(graph_proj, circuity_dist='euclidean')
stats
{'n': 124,
'm': 249,
'k_avg': 4.016129032258065,
'intersection_count': 116,
'streets_per_node_avg': 3.217741935483871,
'streets_per_node_counts': {0: 0, 1: 8, 2: 1, 3: 71, 4: 44},
'streets_per_node_proportion': {0: 0.0,
1: 0.06451612903225806,
2: 0.008064516129032258,
3: 0.5725806451612904,
4: 0.3548387096774194},
'edge_length_total': 19986.84000000001,
'edge_length_avg': 80.2684337349398,
'street_length_total': 13671.708999999999,
'street_length_avg': 74.70879234972676,
'street_segments_count': 183,
'node_density_km': None,
'intersection_density_km': None,
'edge_density_km': None,
'street_density_km': None,
'circuity_avg': 1.0244573582451892,
'self_loop_proportion': 0.0,
'clean_intersection_count': None,
'clean_intersection_density_km': None}
To be able to extract the more advanced statistics (and some of the missing ones above) from the street network, it is required to have information about the coverage area of the network. Let’s calculate the area of the convex hull of the street network and see what we can get.
# Get the Convex Hull of the network
convex_hull = edges_proj.unary_union.convex_hull
# Show output
convex_hull

Now we can use the Convex Hull above to calculate extended statistics for the network. As some of the metrics are produced separately for each node, they produce a lot of output. Here, we combine the basic and extended statistics into one pandas Series to keep things in more compact form.
# Calculate the area
area = convex_hull.area
# Calculate statistics with density information
stats = ox.basic_stats(graph_proj, area=area)
extended_stats = ox.extended_stats(graph_proj, ecc=True, cc=True)
# Add extened statistics to the basic statistics
for key, value in extended_stats.items():
stats[key] = value
# Convert the dictionary to a Pandas series for a nicer output
pd.Series(stats)
n 124
m 249
k_avg 4.01613
intersection_count 116
streets_per_node_avg 3.21774
streets_per_node_counts {0: 0, 1: 8, 2: 1, 3: 71, 4: 44}
streets_per_node_proportion {0: 0.0, 1: 0.06451612903225806, 2: 0.00806451...
edge_length_total 19986.8
edge_length_avg 80.2684
street_length_total 13671.7
street_length_avg 74.7088
street_segments_count 183
node_density_km 148.885
intersection_density_km 139.28
edge_density_km 23997.9
street_density_km 16415.4
circuity_avg 1.27042e-05
self_loop_proportion 0
clean_intersection_count None
clean_intersection_density_km None
avg_neighbor_degree {25216594: 2.0, 25238874: 2.0, 25238944: 1.0, ...
avg_neighbor_degree_avg 2.14315
avg_weighted_neighbor_degree {25216594: 0.04891769597651951, 25238874: 0.12...
avg_weighted_neighbor_degree_avg 0.0838883
degree_centrality {25216594: 0.024390243902439025, 25238874: 0.0...
degree_centrality_avg 0.0326515
clustering_coefficient {25216594: 0, 25238874: 0, 25238944: 0, 252915...
clustering_coefficient_avg 0.0954301
clustering_coefficient_weighted {25216594: 0, 25238874: 0, 25238944: 0, 252915...
clustering_coefficient_weighted_avg 0.0166188
pagerank {25216594: 0.008700928735150002, 25238874: 0.0...
pagerank_max_node 25416262
pagerank_max 0.0239181
pagerank_min_node 1008183915
pagerank_min 0.00142892
eccentricity {25216594: 1915.0230000000001, 25238874: 1788....
diameter 2153.57
radius 1007.07
center [1372376937]
periphery [319896278]
closeness_centrality {25216594: 0.0009353926092551588, 25238874: 0....
closeness_centrality_avg 0.00143689
dtype: object
As we can see, now we have a LOT of information about our street network that can be used to understand its structure. We can for example see that the average node density in our network is 149 nodes/km and that the total edge length of our network is almost 20 kilometers.
Furthermore, we can see that the degree centrality of our network is on average 0.0326515. Degree is a simple centrality measure that counts how many neighbors a node has (here a fraction of nodes it is connected to). Another interesting measure is the PageRank that measures the importance of specific node in the graph. Here we can see that the most important node in our graph seem to a node with osmid 25416262. PageRank was the algorithm that Google first developed (Larry Page & Sergei Brin) to order the search engine results and became famous for.
You can read the Wikipedia article about different centrality measures if you are interested what the other centrality measures mean.
Shortest path analysis¶
Let’s now calculate the shortest path between two points using the shortest path function in Networkx.
Origin and destination points¶
First we need to specify the source and target locations for our route. If you are familiar with the Kamppi area, you can specify a custom placename as a source location. Or, you can choose from these options:
Maria 01 and old hospital area and current startup hub
Tennispalatsi - a big movie theatre (note! Routing in the drivable network will fail with this input).
We could figure out the coordinates for these locations manually, and create shapely points based on the coordinates. However, it is more handy to fetch the location of our source destination directly from OSM:
# Set place name
place = "Maria 01, Helsinki"
# Geocode the place name
geocoded_place = ox.geocode_to_gdf(place)
# Check the result
geocoded_place
| geometry | place_name | bbox_north | bbox_south | bbox_east | bbox_west | |
|---|---|---|---|---|---|---|
| 0 | POLYGON ((24.92122 60.16644, 24.92126 60.16625... | Maria 01, Baana, Hietalahti, Kamppi, Southern ... | 60.167525 | 60.16624 | 24.92317 | 24.921221 |
As output, we received the building footprint. From here, we can get the centroid as the source location of our shortest path analysis. However, we first need to project the data into the correct crs:
# Re-project
geocoded_place.to_crs(CRS(edges_proj.crs), inplace=True)
# Get centroid as shapely point
origin = geocoded_place["geometry"].centroid.values[0]
print(origin)
POINT (384692.1788217347 6671817.486427824)
Great! Now we have defined the origin point of our analysis somewhere in the area of interest.
Next, we still need the destination location. To make things simple, we can set the easternmost node in our road network as the destination. Let’s have another look at our node data:
nodes_proj.head()
| y | x | osmid | lon | lat | highway | geometry | |
|---|---|---|---|---|---|---|---|
| 25216594 | 6.671580e+06 | 384631.322372 | 25216594 | 24.921057 | 60.164794 | NaN | POINT (384631.322 6671580.071) |
| 25238874 | 6.671454e+06 | 384625.787221 | 25238874 | 24.921028 | 60.163665 | NaN | POINT (384625.787 6671454.380) |
| 25238944 | 6.671562e+06 | 384643.473274 | 25238944 | 24.921286 | 60.164631 | NaN | POINT (384643.473 6671561.534) |
| 25291537 | 6.671500e+06 | 385515.553244 | 25291537 | 24.937023 | 60.164325 | NaN | POINT (385515.553 6671500.134) |
| 25291564 | 6.671673e+06 | 385779.207015 | 25291564 | 24.941674 | 60.165948 | NaN | POINT (385779.207 6671672.709) |
We can find the easternmost nodes based on the x coordinates:
# Retrieve the maximum x value (i.e. the most eastern)
maxx = nodes_proj['x'].max()
Let’s find out the coresponding point geometries for these noodes.
We can do this by using the .loc function of Pandas that we have used already many times in earlier tutorials.
# Easternmost point
destination = nodes_proj.loc[nodes_proj['x']==maxx, 'geometry'].values[0]
print(destination)
POINT (385855.0300992894 6671721.810323974)
Nearest node¶
Let’s now find the nearest graph nodes (and their node IDs) to these points using OSMnx get_nearest_node. As a starting point, we have the two Shapely Point objects we just defined as the origin and destination locations.
According to the documentation of this function, we need to parse Point coordinates as coordinate-tuples in this order: latitude, longitude(or y, x). As our data is now projected to UTM projection, we need to specify with method parameter that the function uses 'euclidean' distances to calculate the distance from the point to the closest node (with decimal derees, use 'haversine', which determines the great-circle distances). The method parameter is important if you want to know the actual distance between the Point and the closest node which you can retrieve by specifying parameter return_dist=True.
# Get origin x and y coordinates
orig_xy = (origin.y, origin.x)
# Get target x and y coordinates
target_xy = (destination.y, destination.x)
# Find the node in the graph that is closest to the origin point (here, we want to get the node id)
orig_node_id = ox.get_nearest_node(graph_proj, orig_xy, method='euclidean')
orig_node_id
319896278
# Find the node in the graph that is closest to the target point (here, we want to get the node id)
target_node_id = ox.get_nearest_node(graph_proj, target_xy, method='euclidean')
target_node_id
317703609
Now we have the IDs for the closest nodes that were found from the graph to the origin and target points that we specified.
Let’s retrieve the node information from the nodes_proj GeoDataFrame by passing the ids to the loc indexer
# Retrieve the rows from the nodes GeoDataFrame based on the node id (node id is the index label)
orig_node = nodes_proj.loc[orig_node_id]
target_node = nodes_proj.loc[target_node_id]
Let’s also create a GeoDataFrame that contains these points
# Create a GeoDataFrame from the origin and target points
od_nodes = gpd.GeoDataFrame([orig_node, target_node], geometry='geometry', crs=nodes_proj.crs)
od_nodes.head()
| y | x | osmid | lon | lat | highway | geometry | |
|---|---|---|---|---|---|---|---|
| 319896278 | 6.671803e+06 | 384645.074633 | 319896278 | 24.921178 | 60.166794 | NaN | POINT (384645.075 6671802.525) |
| 317703609 | 6.671722e+06 | 385855.030099 | 317703609 | 24.943012 | 60.166410 | traffic_signals | POINT (385855.030 6671721.810) |
Okay, as a result we got now the closest node IDs of our origin and target locations. As you can see, the index in this GeoDataFrame corresponds to the IDs that we found with get_nearest_node() function.
Routing¶
Now we are ready to do the routing and find the shortest path between the origin and target locations
by using the shortest_path() function of networkx.
With weight -parameter we can specify that 'length' attribute should be used as the cost impedance in the routing. If specifying the weight parameter, NetworkX will use by default Dijkstra’s algorithm to find the optimal route. We need to specify the graph that is used for routing, and the origin ID (source) and the target ID in between the shortest path will be calculated:
# Calculate the shortest path
route = nx.shortest_path(G=graph_proj, source=orig_node_id, target=target_node_id, weight='length')
# Show what we have
print(route)
[319896278, 1382320455, 25216594, 1372425714, 25238874, 1372425713, 529507771, 258188404, 1372318829, 159619609, 175832743, 1372425705, 1007980689, 149143065, 268177652, 60004721, 1372376937, 1372441170, 60170471, 1377211668, 1377211666, 25291565, 25291564, 317703609]
As a result we get a list of all the nodes that are along the shortest path.
We could extract the locations of those nodes from the
nodes_projGeoDataFrame and create a LineString presentation of the points, but luckily, OSMnx can do that for us and we can plot shortest path by usingplot_graph_route()function:
# Plot the shortest path
fig, ax = ox.plot_graph_route(graph_proj, route)
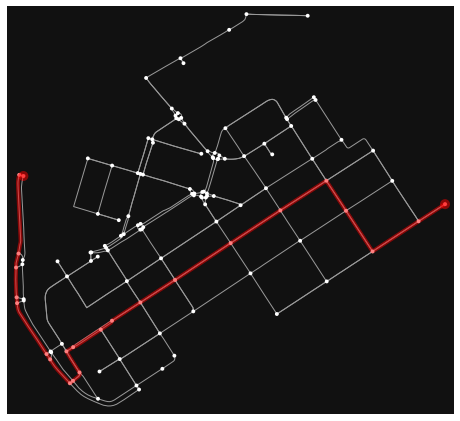
Nice! Now we have the shortest path between our origin and target locations. Being able to analyze shortest paths between locations can be valuable information for many applications. Here, we only analyzed the shortest paths based on distance but quite often it is more useful to find the optimal routes between locations based on the travelled time. Here, for example we could calculate the time that it takes to cross each road segment by dividing the length of the road segment with the speed limit and calculate the optimal routes by taking into account the speed limits as well that might alter the result especially on longer trips than here.
Saving shortest paths to disk¶
Quite often you need to save the route e.g. as a Shapefile. Hence, let’s continue still a bit and see how we can make a Shapefile of our route with some information associated with it.
First we need to get the nodes that belong to the shortest path:
# Get the nodes along the shortest path
route_nodes = nodes_proj.loc[route]
route_nodes
| y | x | osmid | lon | lat | highway | geometry | |
|---|---|---|---|---|---|---|---|
| 319896278 | 6.671803e+06 | 384645.074633 | 319896278 | 24.921178 | 60.166794 | NaN | POINT (384645.075 6671802.525) |
| 1382320455 | 6.671806e+06 | 384633.394361 | 1382320455 | 24.920966 | 60.166820 | NaN | POINT (384633.394 6671805.824) |
| 25216594 | 6.671580e+06 | 384631.322372 | 25216594 | 24.921057 | 60.164794 | NaN | POINT (384631.322 6671580.071) |
| 1372425714 | 6.671540e+06 | 384624.178763 | 1372425714 | 24.920951 | 60.164432 | NaN | POINT (384624.179 6671539.986) |
| 25238874 | 6.671454e+06 | 384625.787221 | 25238874 | 24.921028 | 60.163665 | NaN | POINT (384625.787 6671454.380) |
| 1372425713 | 6.671438e+06 | 384627.187049 | 1372425713 | 24.921063 | 60.163516 | NaN | POINT (384627.187 6671437.809) |
| 529507771 | 6.671292e+06 | 384711.598018 | 529507771 | 24.922665 | 60.162230 | NaN | POINT (384711.598 6671291.757) |
| 258188404 | 6.671276e+06 | 384721.946323 | 258188404 | 24.922860 | 60.162095 | NaN | POINT (384721.946 6671276.431) |
| 1372318829 | 6.671208e+06 | 384778.761107 | 1372318829 | 24.923922 | 60.161496 | NaN | POINT (384778.761 6671207.956) |
| 159619609 | 6.671215e+06 | 384787.503483 | 159619609 | 24.924076 | 60.161561 | NaN | POINT (384787.503 6671214.847) |
| 175832743 | 6.671239e+06 | 384806.144893 | 175832743 | 24.924398 | 60.161782 | NaN | POINT (384806.145 6671238.924) |
| 1372425705 | 6.671299e+06 | 384768.805480 | 1372425705 | 24.923691 | 60.162314 | NaN | POINT (384768.805 6671299.364) |
| 1007980689 | 6.671311e+06 | 384787.969869 | 1007980689 | 24.924029 | 60.162428 | NaN | POINT (384787.970 6671311.466) |
| 149143065 | 6.671362e+06 | 384867.310755 | 149143065 | 24.925429 | 60.162901 | NaN | POINT (384867.311 6671361.707) |
| 268177652 | 6.671387e+06 | 384899.509087 | 268177652 | 24.925995 | 60.163139 | crossing | POINT (384899.509 6671387.230) |
| 60004721 | 6.671440e+06 | 384980.836116 | 60004721 | 24.927429 | 60.163634 | NaN | POINT (384980.836 6671439.807) |
| 1372376937 | 6.671504e+06 | 385080.337968 | 1372376937 | 24.929185 | 60.164240 | NaN | POINT (385080.338 6671504.242) |
| 1372441170 | 6.671610e+06 | 385239.956998 | 1372441170 | 24.931999 | 60.165235 | NaN | POINT (385239.957 6671610.080) |
| 60170471 | 6.671704e+06 | 385382.616738 | 60170471 | 24.934515 | 60.166117 | NaN | POINT (385382.617 6671703.996) |
| 1377211668 | 6.671789e+06 | 385514.573340 | 1377211668 | 24.936843 | 60.166917 | NaN | POINT (385514.573 6671789.024) |
| 1377211666 | 6.671703e+06 | 385570.886277 | 1377211666 | 24.937906 | 60.166160 | NaN | POINT (385570.886 6671702.892) |
| 25291565 | 6.671586e+06 | 385647.124210 | 25291565 | 24.939344 | 60.165135 | traffic_signals | POINT (385647.124 6671586.216) |
| 25291564 | 6.671673e+06 | 385779.207015 | 25291564 | 24.941674 | 60.165948 | NaN | POINT (385779.207 6671672.709) |
| 317703609 | 6.671722e+06 | 385855.030099 | 317703609 | 24.943012 | 60.166410 | traffic_signals | POINT (385855.030 6671721.810) |
As we can see, now we have all the nodes that were part of the shortest path as a GeoDataFrame.
Now we can create a LineString out of the Point geometries of the nodes:
from shapely.geometry import LineString, Point
# Create a geometry for the shortest path
route_line = LineString(list(route_nodes.geometry.values))
route_line

Now we have the route as a LineString geometry.
Let’s make a GeoDataFrame out of it having some useful information about our route such as a list of the osmids that are part of the route and the length of the route.
# Create a GeoDataFrame
route_geom = gpd.GeoDataFrame([[route_line]], geometry='geometry', crs=edges_proj.crs, columns=['geometry'])
# Add a list of osmids associated with the route
route_geom.loc[0, 'osmids'] = str(list(route_nodes['osmid'].values))
# Calculate the route length
route_geom['length_m'] = route_geom.length
route_geom.head()
| geometry | osmids | length_m | |
|---|---|---|---|
| 0 | LINESTRING (384645.075 6671802.525, 384633.394... | [319896278, 1382320455, 25216594, 1372425714, ... | 2152.495705 |
Now we have a GeoDataFrame that we can save to disk. Let’s still confirm that everything is ok by plotting our route on top of our street network and some buildings, and plot also the origin and target points on top of our map.
Get buildings:
tags = {'building': True}
buildings = ox.geometries_from_place(place_name, tags)
re-project buildings
buildings_proj = buildings.to_crs(CRS(edges_proj.crs))
/opt/conda/lib/python3.8/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: `should_run_async` will not call `transform_cell` automatically in the future. Please pass the result to `transformed_cell` argument and any exception that happen during thetransform in `preprocessing_exc_tuple` in IPython 7.17 and above.
and should_run_async(code)
Let’s now plot the route and the street network elements to verify that everything is as it should:
# Plot edges and nodes
ax = edges_proj.plot(linewidth=0.75, color='gray')
ax = nodes_proj.plot(ax=ax, markersize=2, color='gray')
# Add buildings
ax = buildings_proj.plot(ax=ax, facecolor='khaki', alpha=0.7)
# Add the route
ax = route_geom.plot(ax=ax, linewidth=2, linestyle='--', color='red')
# Add the origin and destination nodes of the route
ax = od_nodes.plot(ax=ax, markersize=24, color='green')
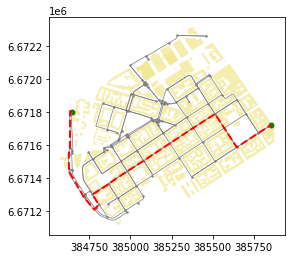
Great everything seems to be in order! As you can see, now we have a full control of all the elements of our map and we can use all the aesthetic properties that matplotlib provides to modify how our map will look like. Now we are almost ready to save our data into disk.
As there are certain columns with such data values that Shapefile format does not support (such as
listorboolean), we need to convert those into strings to be able to export the data to Shapefile:
# Columns with invalid values
invalid_cols = ['lanes', 'maxspeed', 'name', 'oneway', 'osmid']
# Iterate over invalid columns and convert them to string format
for col in invalid_cols:
edges_proj[col] = edges_proj[col].astype(str)
print(edges_proj.dtypes)
osmid object
oneway object
lanes object
name object
highway object
maxspeed object
length float64
geometry geometry
junction object
bridge object
access object
u int64
v int64
key int64
dtype: object
/opt/conda/lib/python3.8/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: `should_run_async` will not call `transform_cell` automatically in the future. Please pass the result to `transformed_cell` argument and any exception that happen during thetransform in `preprocessing_exc_tuple` in IPython 7.17 and above.
and should_run_async(code)
Now we can see that most of the attributes are of type object that quite often (such as ours here) refers to a string type of data.
Now we are finally ready to parse the output filepaths and save the data into disk:
import os
# Parse the place name for the output file names (replace spaces with underscores and remove commas)
place_name_out = place_name.replace(' ', '_').replace(',','')
# Output directory
out_dir = "data"
# Parse output file paths
streets_out = os.path.join(out_dir, "%s_streets.shp" % place_name_out)
route_out = os.path.join(out_dir, "Route_from_a_to_b_at_%s.shp" % place_name_out)
nodes_out = os.path.join(out_dir, "%s_nodes.shp" % place_name_out)
buildings_out = os.path.join(out_dir, "%s_buildings.shp" % place_name_out)
od_out = os.path.join(out_dir, "%s_route_OD_points.shp" % place_name_out)
# Save files
edges_proj.to_file(streets_out)
route_geom.to_file(route_out)
nodes_proj.to_file(nodes_out)
od_nodes.to_file(od_out)
buildings[['geometry', 'name', 'addr:street']].to_file(buildings_out)
Great, now we have saved all the data that was used to produce the maps as Shapefiles.